
CV_learning_notes(3)
DL Related Network Part
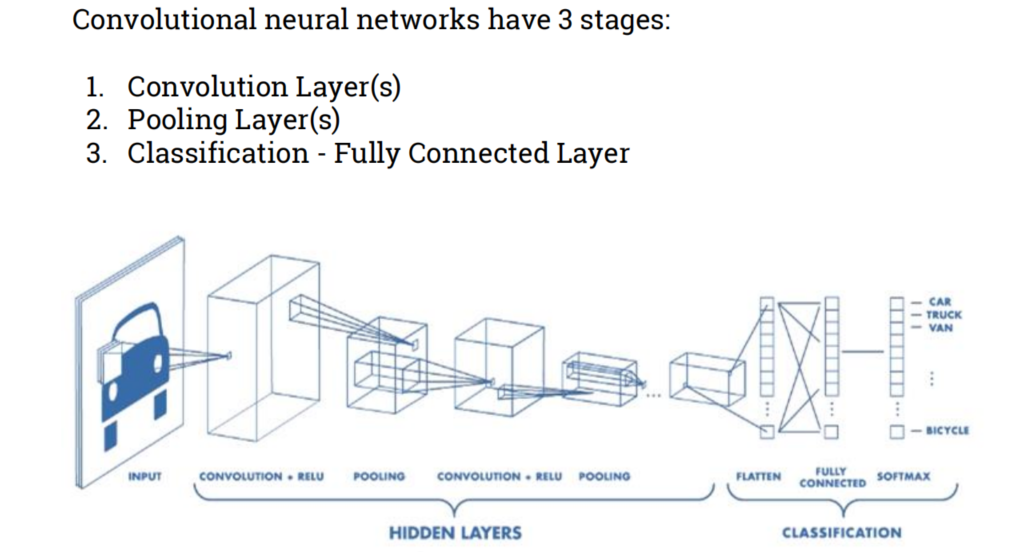
CNN
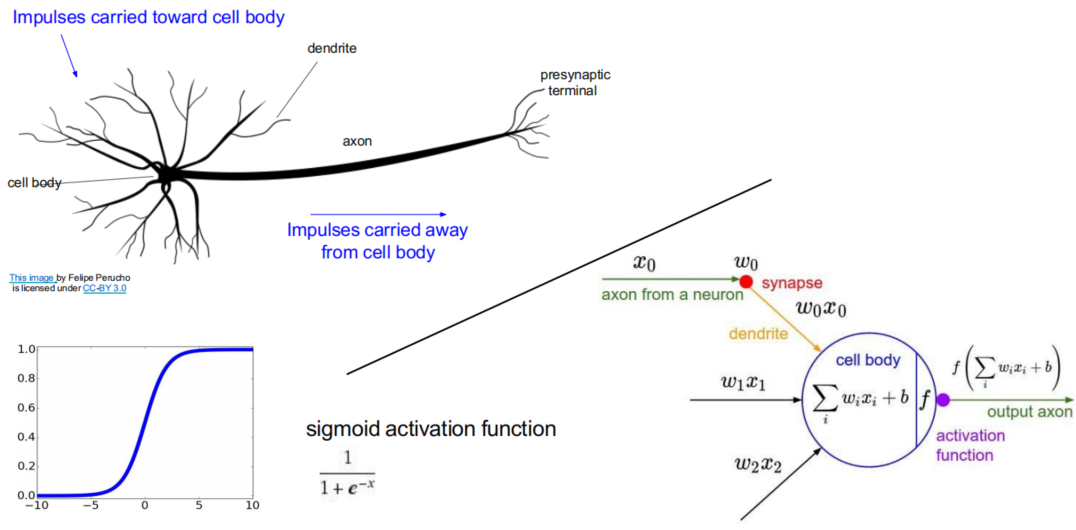
- Neural Network(MLP多层感知机/全连接网络)
- Goal: 引入激活函数(activation function),即可得到非线性分类器
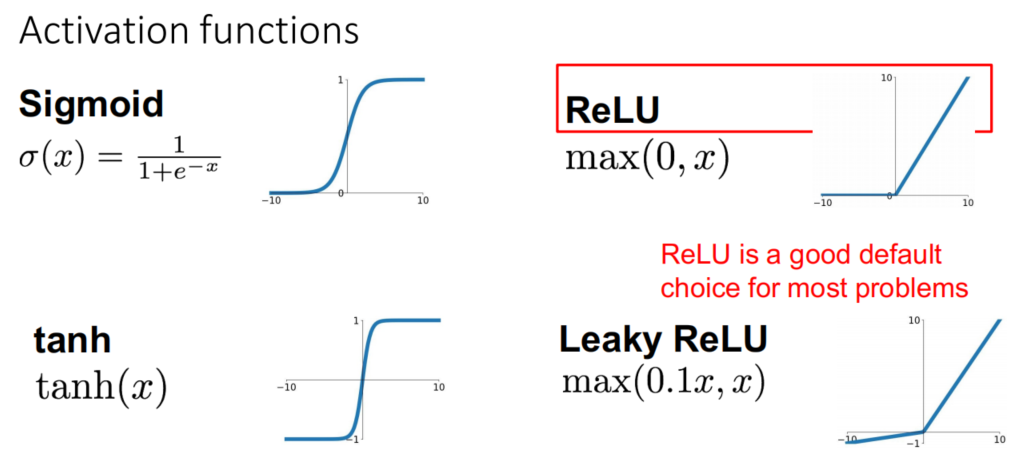
- Activation fucntions
- Process: forward passing + backward propagation(Gradient descent)
- Convolutional Neural Networks
- Overview
- Convolution layer
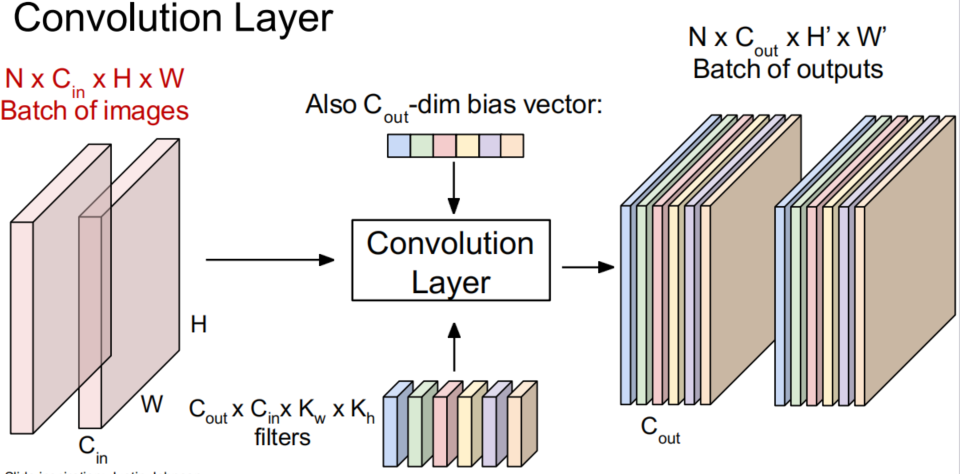
N表示image的batch数量Cin表示图片3维维度HW表示图片的长宽Cout表示输出Activation map的层数KwKh表示filter的长宽H'W'表示卷积后输出Activation map的长宽
- 无padding时输出大小
- 有padding时输出大小
- 有参:
- Pooling layer
- makes the representations smaller and more manageable
- operates over each activation map independently(layer by layer)
- 无参
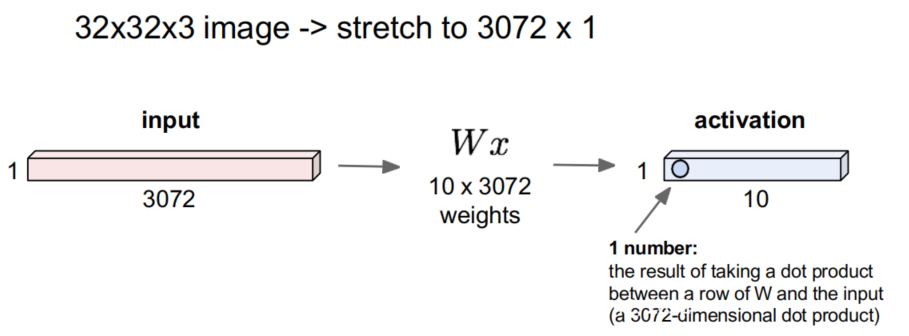
- Fully-connected layer
- The reduced form of our image is flattened into a column vector and is fed through a feed forward neural network
- Overview

CNN architecture
RNN-GAN
-
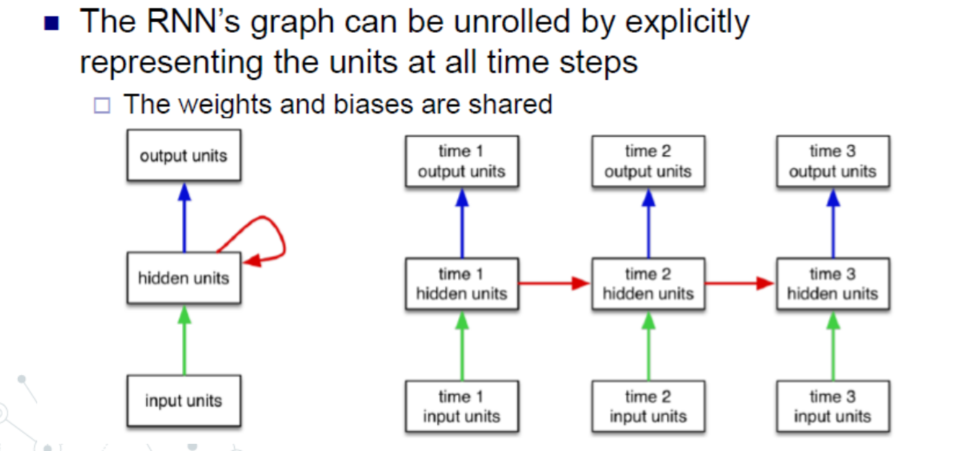
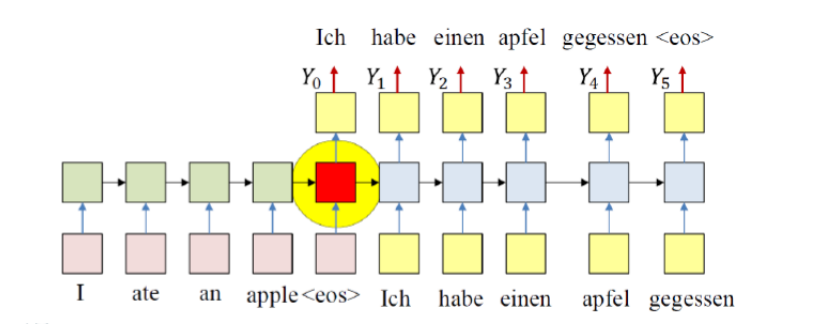
RNN(Recurrent Neural Network) 短期记忆
- Markov assumption:
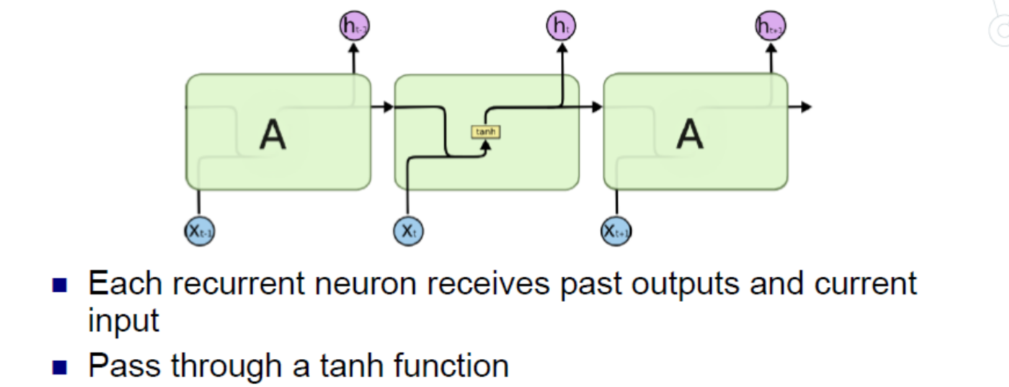
- Formula:
- 共享参数和激活函数
- 一般可作为自学习,即上一步的输出作为这一步的输入!!!
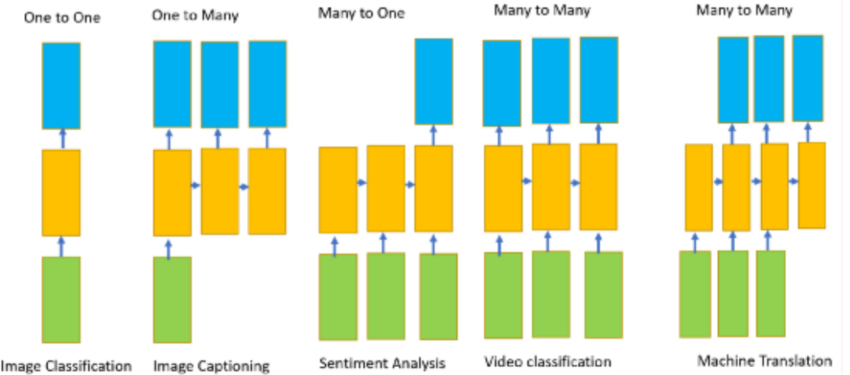
- Different types
- Training example
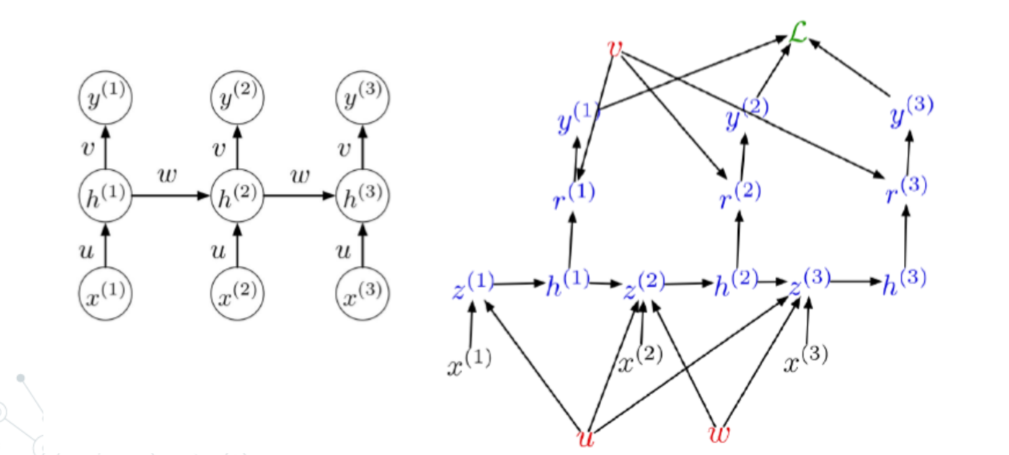
- 对于Loss,要前向全部序列计算;对于梯度下降,要反向全部序列计算
- 优化:
- chunks!!!
- Problem:
- 短期记忆
- 梯度消失和爆炸
- 由于反向传播是linear,而正向传播由于激活函数的存在是非线性的
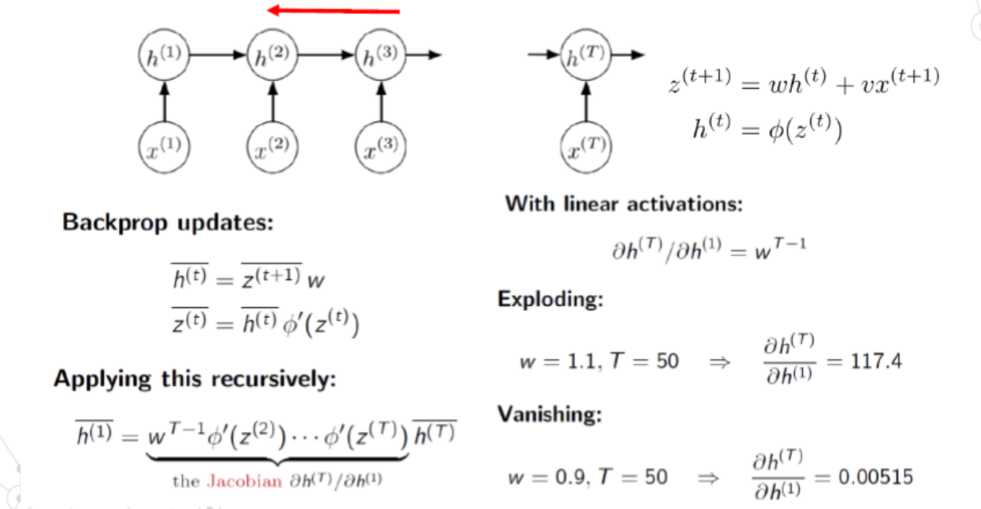
-
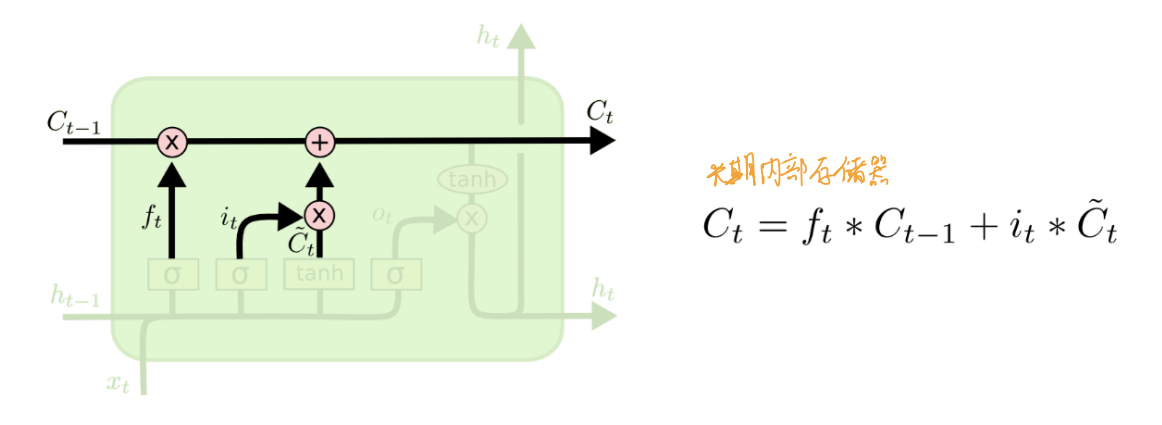
LSTM 长期记忆(在RNN的基础上额外加入了记忆信号)
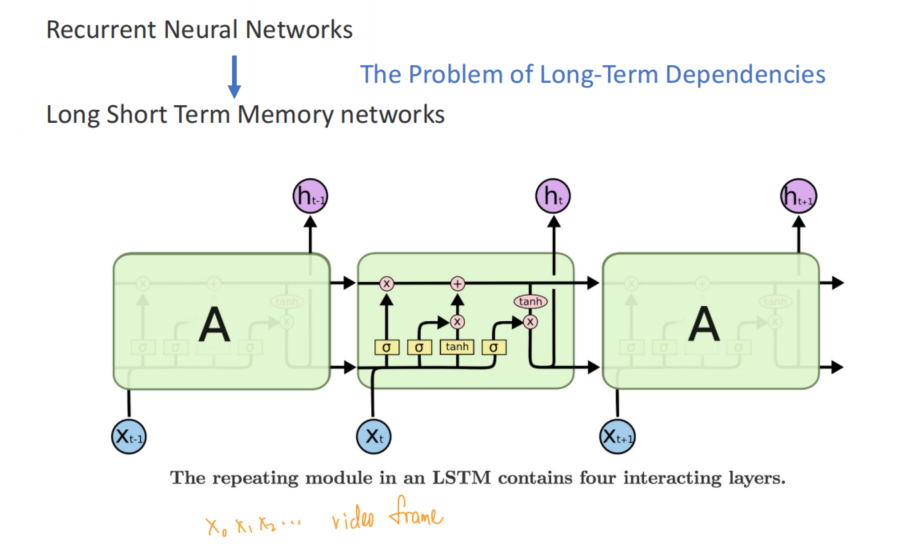
- 遗忘门
- 输入门
- 更新门
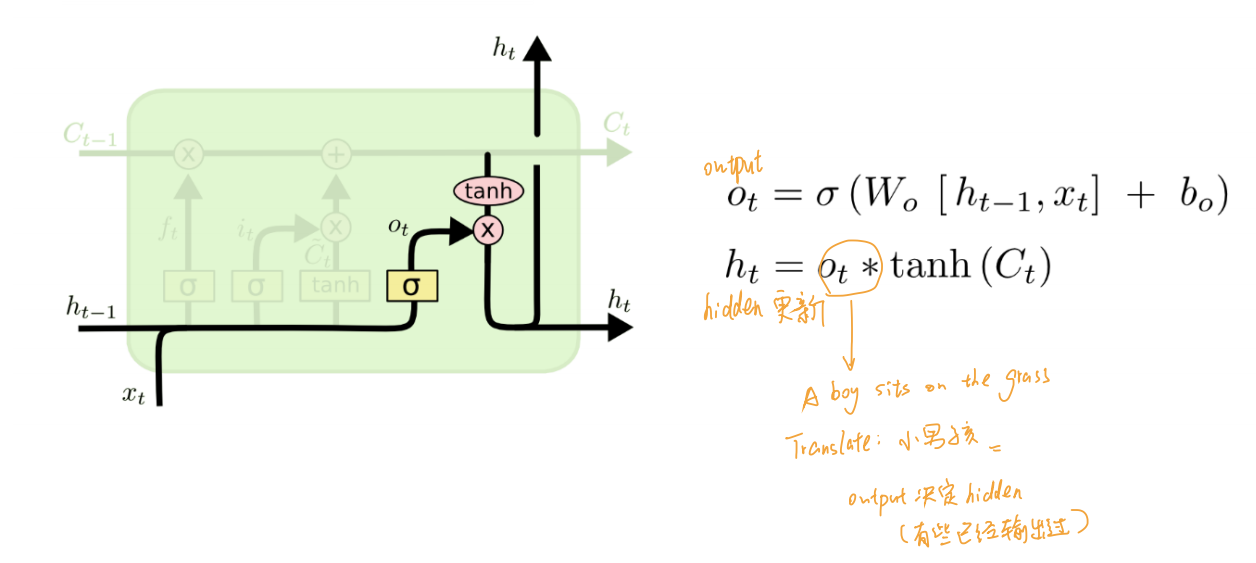
- 输出门
- Eg.
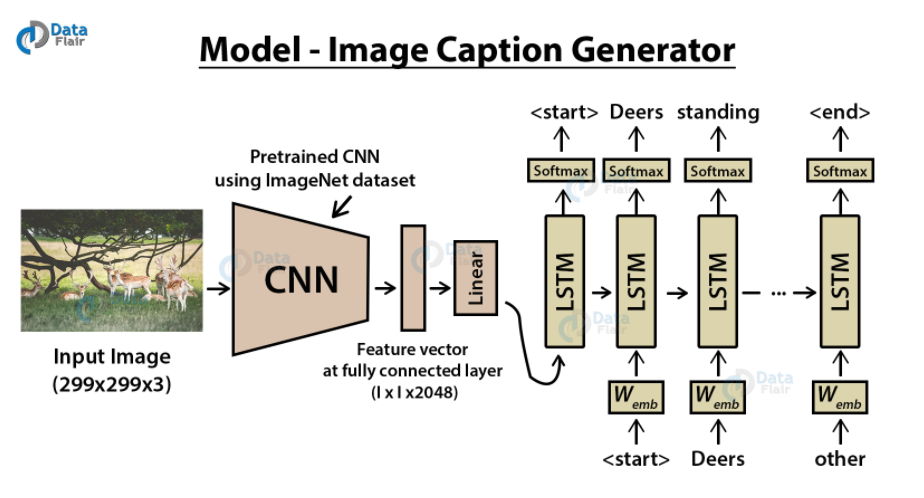
-
Attention model
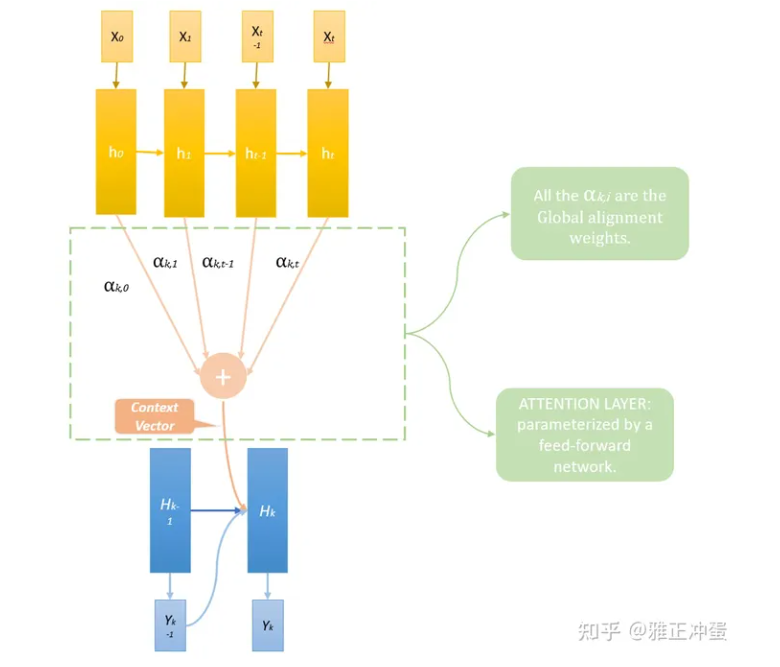
h(t)是Encoder网络的隐藏层中间输出C(t)是时刻t的上下文向量(Context Vector),而这些分配的权重我们称之为全局对齐权重(Global Alignment Weights)-
- 加性模型
- 乘法模型
- 点积模型
- 缩放点积模型
- , 即softmax操作
-
H(t)是decoder网络的隐藏层输出- 而RNN模型,中间状态由于来自于输入网络最后的隐藏层,一般来说它是一个大小固定的向量。既然是大小固定的向量,那么它能储存的信息就是有限的,当句子长度不断变长,由于后方的decoder网络的所有信息都来自中间状态,中间状态需要表达的信息就越来越多。
- Process
-
- Encoder网络按照原来的方法计算出
-
- Decoder网络种对于第K个输出词语
- 计算出对应的全局对齐权重
- 计算得到加权求和
-
- 计算新的, using
-
- 计算最终的
-
- k++, 直至网络输出
-
-
DGN
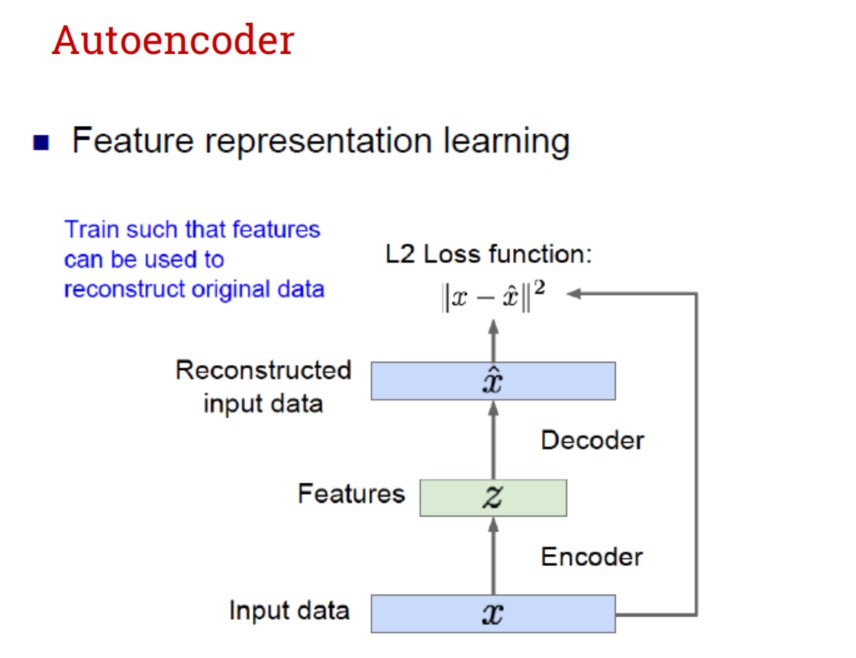
- Auto-encoder
- 无监督学习的一种
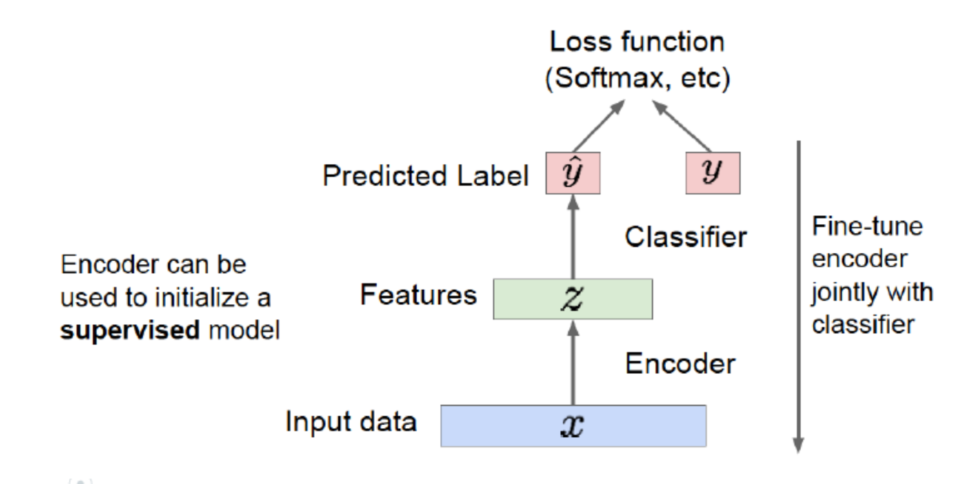
- 也可用于有监督模型中,通过去标签的数据训练得到decoder
- 无监督学习的一种
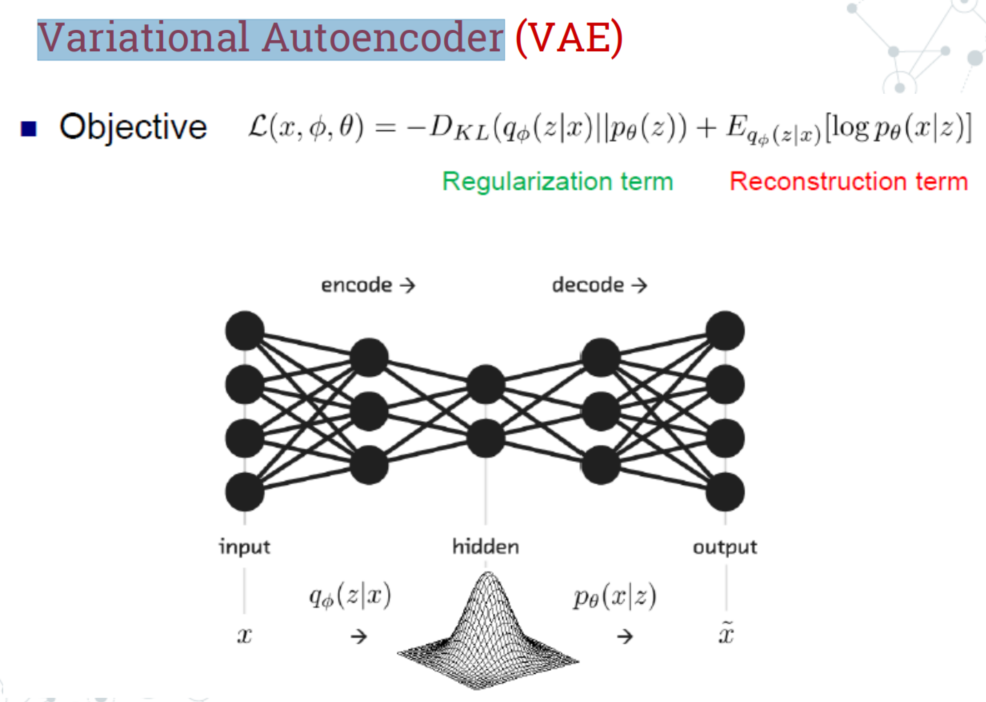
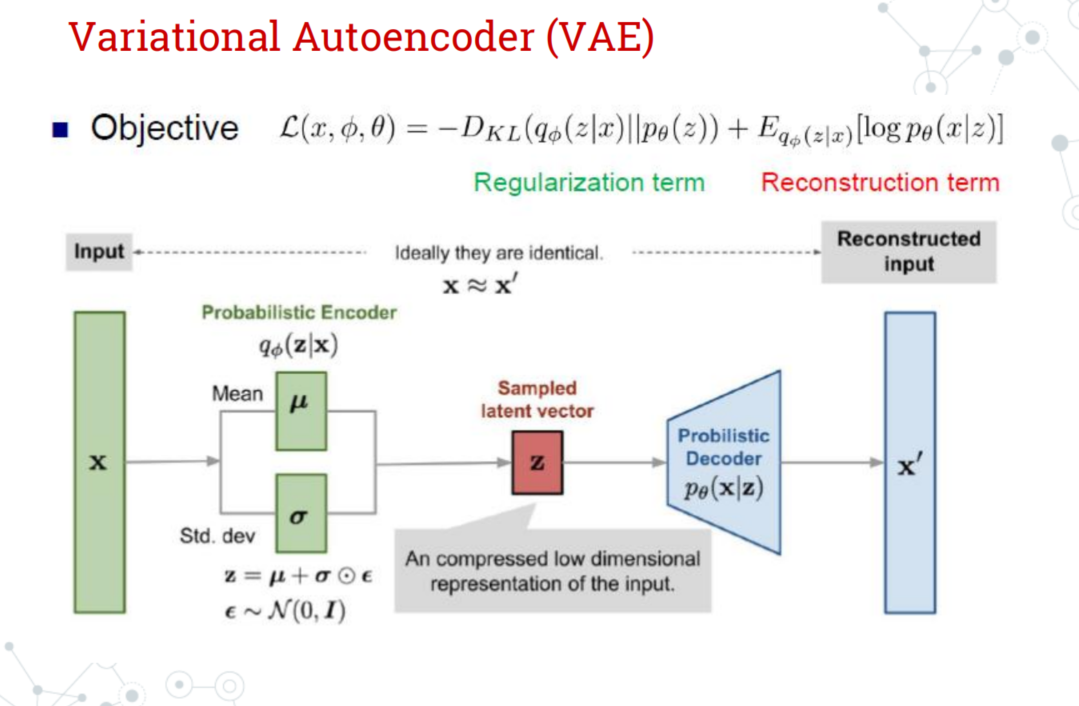
- VAE(Variational Autoencoder)
- GAN(Generative Adversarial Networks)
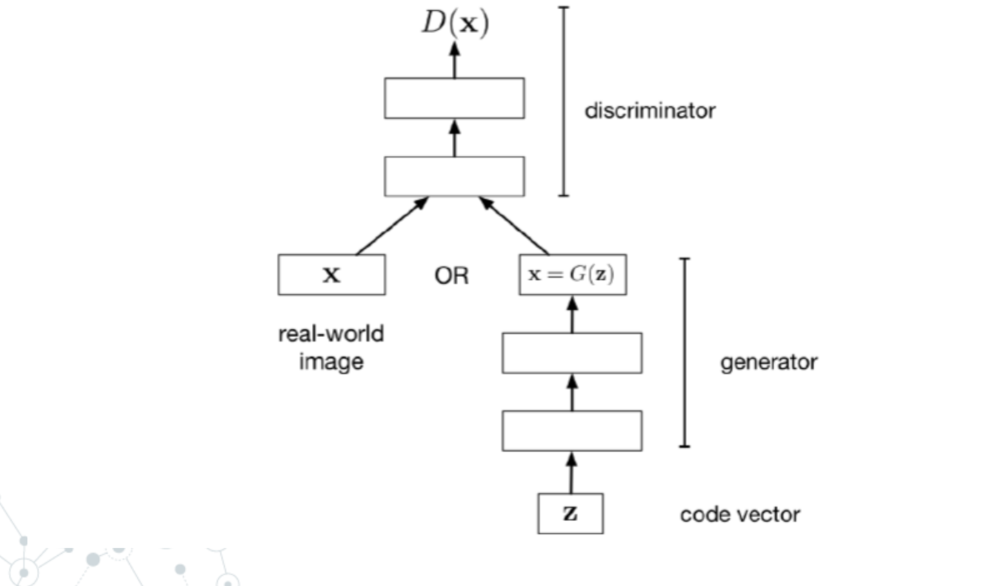
- For generator, we are trying to get 更加逼真的 image to increase loss.
- For discriminator, we are trying to determine more correctly, to reduce loss
- 训练过程可以视为双人的zero-sum games
- Auto-encoder
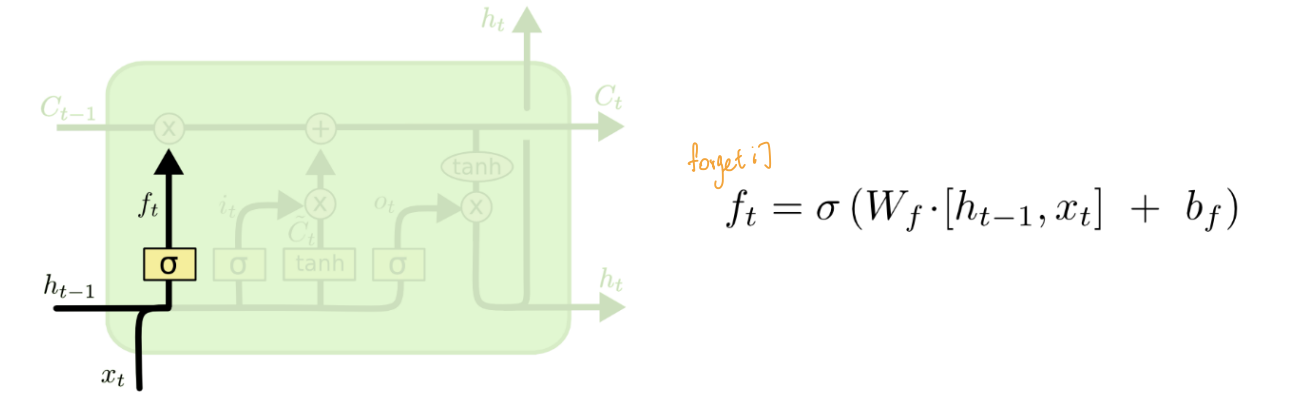
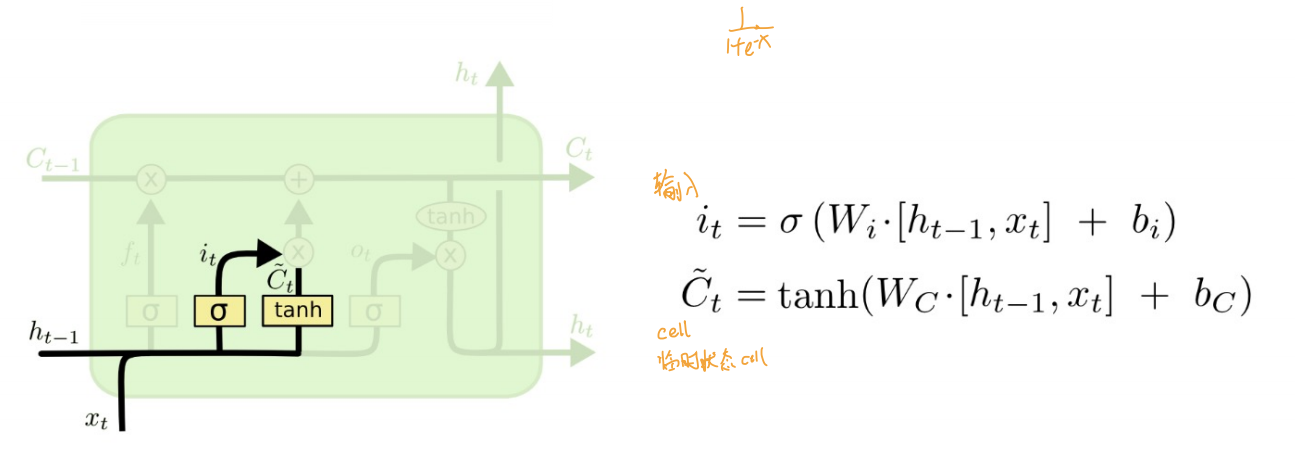

All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.








